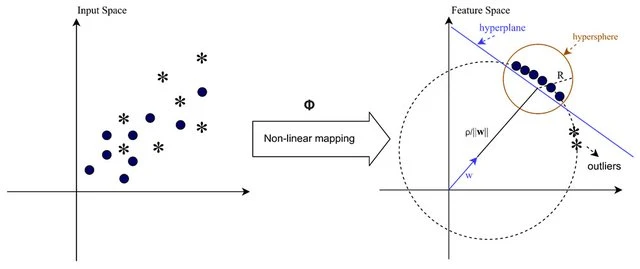
Anomaly detection (outlier detection, novelty detection) is the identification of rare observations that
differ substantially from the vast majority of the data \(^4\).
I would like to point out an important distinction \(^3\):
Outlier detection: The training data contains outliers. Estimators try to fit the regions where the
training data is the most concentrated.
Novelty detection: The training data does not contain outliers. Estimators try to detect whether a new
observation is an outlier.
In short, SVMs separates two classes using a hyperplane with the largest possible margin. On other side,
One-Class SVMs try to identify smallest hypersphere which contains most of the data points\(^4\).
Source: \(^5\)
Example
Dataset was downloaded from ODDS \(^{1,2}\). The original dataset contains
labels but we’ll not use them.
data = arff.loadarff('seismic-bumps.arff')df = pd.DataFrame(data[0])for col in df:ifisinstance(df[col][0], bytes): df[col] = df[col].str.decode("utf8")Markdown(tabulate( df.head(), headers=df.columns))
SVM tries to maximize distance between the hyperplane and the support vectors. If some features have very big
values, they will dominate the other features. So it is important to rescale data while using distance based
methods:
# We assume that the proportion of outliers in the data set is 0.15clf = OCSVM(contamination=0.15)clf.fit(X_train_scaled)X_train_pred = clf.labels_ # binary labels (0: inliers, 1: outliers)X_train_scores = clf.decision_scores_ # raw outlier scoresX_test_pred = clf.predict(X_test_scaled) # outlier labels (0 or 1)X_test_scores = clf.decision_function(X_test_scaled) # outlier scores