n=2000
mu1=3
sigma1=2
mu2=8
sigma2=1
data_sudden = np.random.rand(n) * sigma1 + mu1
data_sudden[1000:] = np.random.randn(1000) * sigma2 + mu2
label = ['Old'] * 2000
label[1000:] = ['New'] * 1000
px.line(data_sudden, title='Sudden Drift', color=label)Why ML models fail in production: Model Drift
How to detect whether your data changed or not.
Introduction
Model drift is a huge problem for machine learning models in production. Model drift reveals itself as a significant increase in error rates for models. To reduce risk, it is essential to track model performance and detect concept drift.
Assume that, given a set of features \(X\) and a target variable \(y\), we are trying to predict the target variable. Then, model drift can occur as following:
- If \(P(y|X)\) conditional distribution changes over time, this is called concept drift;
- if \(P(y)\) distribution changes over time, this is called label drift;
- if \(P(X)\) distribution changes over time, this is called data drift.
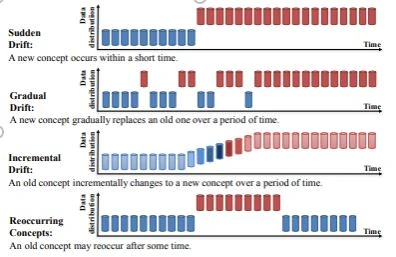
We’ve said that “changes over time”, this change can occur at different shapes:
- Sudden drift: Change occurs in a short period of time.
- Gradual drift: Change occurs gradually.
- Incremental drift: Change occurs incrementally.
- Reoccurring drifts: Some time after a change occurs, the old distribution comes again.
Methods for detecting model drift
Kolmogorov-Smirnov (KS) Test & Chi-squared Test
These sets used for compare two statistical distributions. We can apply these tests to compare distributions of training data and post-training data.
Population Stability Index (PSI)
PSI is a measure for determining how much a population shifted over time.
Drift Detection Method / Early Drift Detection Method
Drift Detection Method (DDM) uses a binomial distribution to describe the behavior of a random variable that gives the number of classification errors. If the distribution of the samples is stationary, probability of misclassification will decrease as sample size increases. If the error rate of the learning algorithm increases significantly, it suggests changes in the distribution of classes, and thus providing the signal to update the model \(^5\).
Early Drift Detection Method (EDDM) is a modification of DDM and improves the detection in presence of gradual concept drift \(^5\).
Page-Hinkley method
This change detection method works by computing the observed values and their mean up to the current moment \(^6\).
ADWIN
ADWIN (ADaptive WINdowing) is a popular drift detection method with mathematical guarantees. ADWIN efficiently keeps a variable-length window of recent items; such that it holds that there has no been change in the data distribution. This window is further divided into two sub-windows \((W_0, W_1)\) used to determine if a change has happened. ADWIN compares the average of \(W_0\) and \(W_1\) to confirm that they correspond to the same distribution. Concept drift is detected if the distribution equality no longer holds. Upon detecting a drift, \(W_0\) is replaced by \(W_1\) and a new \(W_0\) is initialized. ADWIN uses a significance value \(\delta\in(0,1)\) to determine if the two sub-windows correspond to the same distribution \(^8\).
Examples
Let’s generate example data:
-
Sudden drift:
-
Gradual drift:
n=2000 mu1=3 sigma1=2 mu2=8 sigma2=1 data_gradual = np.random.rand(n) * sigma1 + mu1 data_gradual[1000:1500] = np.random.choice([mu1, mu2], size=500) + np.random.randn(500) data_gradual[1500:] = np.random.randn(500) * sigma2 + mu2 label = ['Old'] * 2000 label[1000:1500] = ['Switching btw. old & new'] * 500 label[1500:] = ['New'] * 500 px.line(data_gradual, title='Gradual Drift', color=label) -
Incremental drift:
n=2000 mu1=3 sigma1=2 mu2=8 sigma2=1 data_incremental = np.random.rand(n) * sigma1 + mu1 data_incremental[1000:1500] = np.linspace(4, 8, 500) + np.random.randn(500) data_incremental[1500:] = np.random.randn(500) * sigma2 + mu2 label = ['Old'] * 2000 label[1000:1500] = ['Transition'] * 500 label[1500:] = ['New'] * 500 px.line(data_incremental, title='Incremental Drift', color=label) -
Reoccurring drift:
n=2000 mu1=3 sigma1=2 mu2=8 sigma2=1 data_reoccurring = np.random.rand(n) * sigma1 + mu1 data_reoccurring[1000:1500] = np.random.randn(500) * sigma2 + mu2 data_reoccurring[1500:] = np.random.rand(500) * sigma1 + mu1 label = ['Old'] * 2000 label[1000:1500] = ['New'] * 500 label[1500:] = ['Old '] * 500 px.line(data_reoccurring, title='Reoccurring Drift', color=label)
Let’s apply ADWIN method to each series:
-
Sudden drift
from skmultiflow.drift_detection.adwin import ADWIN adwin = ADWIN() for i in range(2000): adwin.add_element(data_sudden[i]) if adwin.detected_change(): print('Change detected in data: ' + str(data_sudden[i]) + ' - at index: ' + str(i))Change detected in data: 8.092633344755715 - at index: 1023 Change detected in data: 9.929671318625031 - at index: 1055 Change detected in data: 9.487942606466301 - at index: 1087Sudden drift was first detected at index 1023, so the method lagged 23 observations.
-
Gradual drift
adwin = ADWIN() for i in range(2000): adwin.add_element(data_gradual[i]) if adwin.detected_change(): print('Change detected in data: ' + str(data_gradual[i]) + ' - at index: ' + str(i))Change detected in data: 3.7276303613439605 - at index: 1087 Change detected in data: 3.5763573220924223 - at index: 1119 Change detected in data: 4.187222721823322 - at index: 1151 Change detected in data: 7.472834846368913 - at index: 1183 Change detected in data: 7.910709686691047 - at index: 1279 Change detected in data: 6.861296525734318 - at index: 1663 Change detected in data: 6.278295128233516 - at index: 1727 Change detected in data: 5.99610175295946 - at index: 1791Gradual drift was first detected at index 1087, so the method lagged 87 observations. After the index 1500, the method gave 3 misalerts.
-
Incremental drift
adwin = ADWIN() for i in range(2000): adwin.add_element(data_incremental[i]) if adwin.detected_change(): print('Change detected in data: ' + str(data_incremental[i]) + ' - at index: ' + str(i))Change detected in data: 5.230485716995449 - at index: 1151 Change detected in data: 7.135720345796623 - at index: 1183 Change detected in data: 6.408763400413527 - at index: 1215 Change detected in data: 6.121233942647503 - at index: 1247 Change detected in data: 5.2509644445949215 - at index: 1279 Change detected in data: 7.032973666011305 - at index: 1311 Change detected in data: 6.825815433971569 - at index: 1343 Change detected in data: 7.094917550861222 - at index: 1375 Change detected in data: 6.021976471064258 - at index: 1407 Change detected in data: 7.563053572886224 - at index: 1471 Change detected in data: 9.326706248481413 - at index: 1503 Change detected in data: 7.410570560565155 - at index: 1535 Change detected in data: 8.318959498454486 - at index: 1567 Change detected in data: 8.425934499842729 - at index: 1599 Change detected in data: 7.461700640162903 - at index: 1791Incremental drift was first detected at index 1151, so the method lagged 151 observations. After the index 1500, the method gave 4 misalerts.
-
Reoccurring drift
adwin = ADWIN() for i in range(2000): adwin.add_element(data_reoccurring[i]) if adwin.detected_change(): print('Change detected in data: ' + str(data_reoccurring[i]) + ' - at index: ' + str(i))Change detected in data: 7.817990447479633 - at index: 1023 Change detected in data: 8.162873100846571 - at index: 1055 Change detected in data: 7.732247538441721 - at index: 1087 Change detected in data: 3.798546626428176 - at index: 1535 Change detected in data: 3.978688037122022 - at index: 1567 Change detected in data: 3.0069507591156173 - at index: 1599 Change detected in data: 3.7546042052686808 - at index: 1631 Change detected in data: 4.746055229599389 - at index: 1663
As seen from the results, sudden changes can be detected early but it can be a challenge that detect gradual and incremental drifts.
Solutions to model drift
- Discard the old data and retrain the model blindly without detecting any concept drift periodically.
- Weight the all data inversly propotional to the age of data, then train the model.
- Use online (incremental) learning. As the new data arrives, retrain the existing model.
Full source code: https://github.com/mrtkp9993/MyDsProjects/tree/main/ConceptDrift
References
\(^2\) https://datatron.com/what-is-model-drift/#:~:text=Concept%20drift%20is%20a%20type,s)%20change(s).
\(^3\) https://deepchecks.com/how-to-detect-concept-drift-with-machine-learning-monitoring/
\(^4\) https://www.analyticsvidhya.com/blog/2021/10/mlops-and-the-importance-of-data-drift-detection/
\(^5\) https://www.revistaespacios.com/a17v38n39/a17v38n39p16.pdf
No matching items
Citation
BibTeX citation:
@online{koptur2022,
author = {Koptur, Murat},
title = {Why {ML} Models Fail in Production: {Model} {Drift}},
date = {2022-09-04},
url = {https://muratkoptur.com/MyDsProjects/ConceptDrift/Analysis},
langid = {en}
}
For attribution, please cite this work as:
Koptur, Murat. 2022. “Why ML Models Fail in Production: Model
Drift.” September 4, 2022. https://muratkoptur.com/MyDsProjects/ConceptDrift/Analysis.