
library(cluster)
library(factoextra)
library(dplyr)
library(ggplot2)
library(NbClust)
library(quantmod)
library(tibble)
library(tidyquant)
library(tidyr)
set.seed(1234)
# Delete the comment for downloading the data
# stock_list <- read.table("bist100_stocks.txt")
# stock_ohlc <- stock_list$V1 |> tq_get()
# saveRDS(stock_ohlc, file="stock_data.rds")
stock_ohlc <- readRDS("stock_data.rds")
# Fix the index data (XU100.IS)
stock_ohlc$date <- as.Date(stock_ohlc$date, format = "%Y-%m-%d")
stock_ohlc <- stock_ohlc %>% mutate(
adjusted = ifelse(
symbol == 'XU100.IS' & date < "2020-07-27", adjusted / 100, adjusted)
)Build Diversified Portfolio with Machine Learning: Clustering method for stock selection
How to create diversified portfolio using clustering.
Introduction
Last time, we analyzed similar stocks in XU30 index and calculated each cluster’s mean return and risk.
Similar method can be used to diversify portfolio and minimizing the risk: we’ll again apply clustering methods to determine different subsets of stocks in the XU100 market. And we select one stock from each cluster and calculate their return and risk and try to beat the market.
Note: We assume that the index components have not changed over the time. For a more realistic calculation, the stocks added to and excluded from the index should also be taken into account.
Data
Read data:
Visualize annual returns of 5 stocks which has most volume:
top_5_by_vol <- stock_ohlc %>%
filter(symbol != "XU100.IS") %>%
group_by(symbol) %>%
summarise(Volume = sum(volume)) %>%
top_n(5)
stock_ohlc %>%
filter(symbol %in% top_5_by_vol$symbol) %>%
group_by(symbol) %>%
tq_transmute(select = adjusted,
mutate_fun = periodReturn,
period = "yearly",
col_rename = "yearly.returns") %>%
ggplot(aes(x = year(date), y = yearly.returns, fill = symbol)) +
geom_bar(position = "dodge", stat = "identity") +
labs(title = "5 Most Active XU100 Stocks",
y = "Returns", x = "", color = "") +
scale_y_continuous(labels = scales::percent) +
theme_tq() +
scale_fill_tq()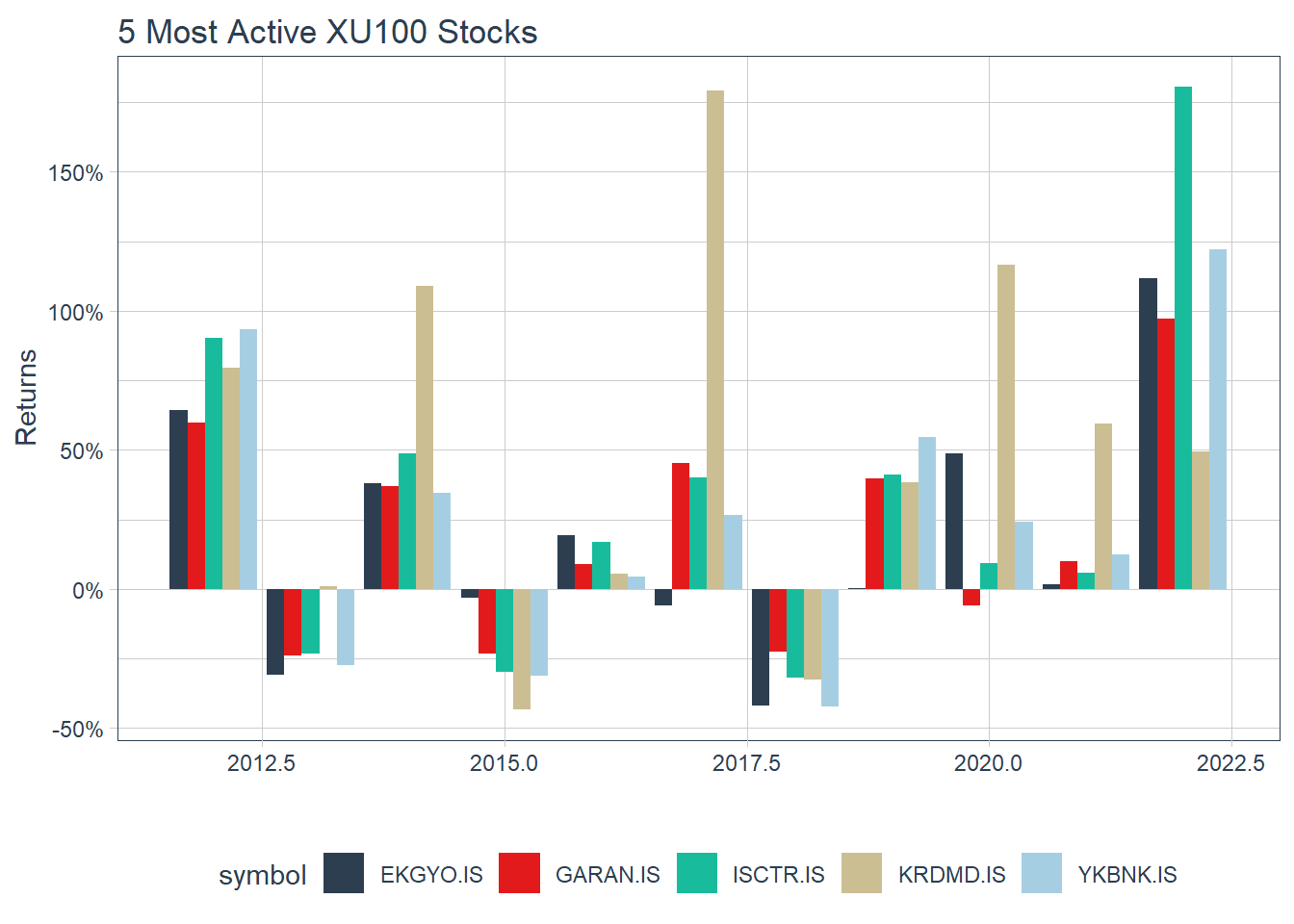
Calculate daily returns for each stock and the market:
daily_returns <- stock_ohlc %>%
group_by(symbol) %>%
tq_transmute(select = adjusted,
mutate_fun = periodReturn,
type = "log",
period = "daily",
col_rename = "daily.returns")Pivot the data:
daily_returns_p <- daily_returns %>%
pivot_wider(names_from = symbol, values_from = daily.returns)Check the NA counts:
colSums(is.na(daily_returns_p)) date XU100.IS AGHOL.IS AKBNK.IS AKCNS.IS AKSA.IS AKSEN.IS ALGYO.IS
0 80 0 0 0 0 0 0
ALARK.IS ALBRK.IS ALKIM.IS AEFES.IS ARCLK.IS ARDYZ.IS ASELS.IS AYDEM.IS
0 0 0 0 0 2111 0 2421
AYGAZ.IS BERA.IS BIMAS.IS BIOEN.IS BRISA.IS CCOLA.IS CANTE.IS CEMTS.IS
0 234 0 2763 0 0 2421 0
CIMSA.IS DEVA.IS DOHOL.IS DOAS.IS EGEEN.IS ECILC.IS EKGYO.IS ENJSA.IS
0 0 0 0 0 0 0 1593
ENKAI.IS ERBOS.IS EREGL.IS ESEN.IS FROTO.IS GLYHO.IS GOZDE.IS GUBRF.IS
0 0 0 2763 0 0 0 0
SAHOL.IS HLGYO.IS HEKTS.IS INDES.IS ISDMR.IS ISFIN.IS ISGYO.IS ISMEN.IS
0 312 0 0 1105 0 0 0
IZMDC.IS KRDMD.IS KARSN.IS KARTN.IS KERVT.IS KRVGD.IS KCHOL.IS KORDS.IS
0 0 0 0 0 2763 0 0
KOZAL.IS KOZAA.IS LOGO.IS MAVI.IS MGROS.IS MPARK.IS NETAS.IS ODAS.IS
0 0 0 1423 0 1596 0 361
OTKAR.IS OYAKC.IS PARSN.IS PGSUS.IS PETKM.IS QUAGR.IS SARKY.IS SASA.IS
0 0 0 405 0 2407 0 0
SELEC.IS SKBNK.IS SOKM.IS TAVHL.IS TKFEN.IS TKNSA.IS TOASO.IS TRGYO.IS
0 0 1664 0 0 98 0 0
TRILC.IS TCELL.IS TMSN.IS TUPRS.IS THYAO.IS TTKOM.IS TTRAK.IS GARAN.IS
2763 0 406 0 0 0 0 0
HALKB.IS ISCTR.IS TSKB.IS TURSG.IS SISE.IS VAKBN.IS ULKER.IS VERUS.IS
0 0 0 0 0 0 0 493
VESBE.IS VESTL.IS YKBNK.IS YATAS.IS ZRGYO.IS ZOREN.IS
0 0 0 0 2763 0 Some stocks have only one day data, 30% or more missing data. We discard them and subset the data:
daily_returns_p <- daily_returns_p %>%
select(where(~ sum(is.na(.x)) < 0.3 * 2764))
indx <- complete.cases(daily_returns_p)
daily_returns_p <- daily_returns_p[indx, ]Check NA count again and date continuity:
print(sum(colSums(is.na(daily_returns_p))))[1] 0print(daily_returns_p %>% select(date) %>% mutate(date_diff = date - lag(date)) %>% filter(date_diff > 3))# A tibble: 37 × 2
date date_diff
<date> <drtn>
1 2014-05-20 4 days
2 2014-07-31 6 days
3 2014-10-08 5 days
4 2015-05-04 4 days
5 2015-07-20 4 days
6 2015-09-28 5 days
7 2016-01-04 4 days
8 2016-07-08 4 days
9 2016-09-16 7 days
10 2017-05-02 4 days
# … with 27 more rowsI’ll omit the gaps for sake of simplicity. Finally, split the market and stocks data:
market_return <- tibble(date=daily_returns_p$date,
daily.return=daily_returns_p$XU100.IS)
stock_returns <- tibble(date=daily_returns_p$date,
daily_returns_p[,!(colnames(daily_returns_p) %in% c("date", "XU100.IS"))])Clustering
Let’s standardize the data:
stock_returns_scaled <- stock_returns %>% select(!date) %>% mutate_each(funs(scale))
stock_returns_scaled[1:5, 1:5]Transpose the data:
stock_returns_scaled <- data.frame(row.names = names(stock_returns_scaled), t(stock_returns_scaled))Find optimum number of clusters for k-means:
nb <- NbClust(stock_returns_scaled, method = "kmeans", min.nc = 3, max.nc = 7, index="gap")
nb$All.index
3 4 5 6 7
-0.9453 -1.4654 -1.6998 -2.1534 -2.6769
$All.CriticalValues
3 4 5 6 7
0.5352 0.2520 0.4748 0.5507 0.1737
$Best.nc
Number_clusters Value_Index
3.0000 -0.9453
$Best.partition
AGHOL.IS AKBNK.IS AKCNS.IS AKSA.IS AKSEN.IS ALGYO.IS ALARK.IS ALBRK.IS
1 3 1 1 1 1 1 1
ALKIM.IS AEFES.IS ARCLK.IS ASELS.IS AYGAZ.IS BERA.IS BIMAS.IS BRISA.IS
1 3 3 1 1 1 3 1
CCOLA.IS CEMTS.IS CIMSA.IS DEVA.IS DOHOL.IS DOAS.IS EGEEN.IS ECILC.IS
3 1 1 2 1 1 1 2
EKGYO.IS ENKAI.IS ERBOS.IS EREGL.IS FROTO.IS GLYHO.IS GOZDE.IS GUBRF.IS
3 1 1 3 3 1 1 1
SAHOL.IS HLGYO.IS HEKTS.IS INDES.IS ISFIN.IS ISGYO.IS ISMEN.IS IZMDC.IS
3 1 1 1 1 1 1 1
KRDMD.IS KARSN.IS KARTN.IS KERVT.IS KCHOL.IS KORDS.IS KOZAL.IS KOZAA.IS
3 1 1 1 3 1 2 2
LOGO.IS MGROS.IS NETAS.IS ODAS.IS OTKAR.IS OYAKC.IS PARSN.IS PGSUS.IS
1 3 1 1 1 1 1 3
PETKM.IS SARKY.IS SASA.IS SELEC.IS SKBNK.IS TAVHL.IS TKFEN.IS TKNSA.IS
3 1 1 2 1 3 3 1
TOASO.IS TRGYO.IS TCELL.IS TMSN.IS TUPRS.IS THYAO.IS TTKOM.IS TTRAK.IS
3 1 3 1 3 3 3 1
GARAN.IS HALKB.IS ISCTR.IS TSKB.IS TURSG.IS SISE.IS VAKBN.IS ULKER.IS
3 3 3 3 1 3 3 3
VERUS.IS VESBE.IS VESTL.IS YKBNK.IS YATAS.IS ZOREN.IS
1 1 1 3 1 1 Optimal cluster count is three, let’s fit and look cluster contents:
km_model <- kmeans(stock_returns_scaled, 3)
fviz_cluster(object = km_model,
data = stock_returns_scaled,
ellipse.type = "norm",
geom = "text",
palette = "jco",
main = "",
ggtheme = theme_minimal())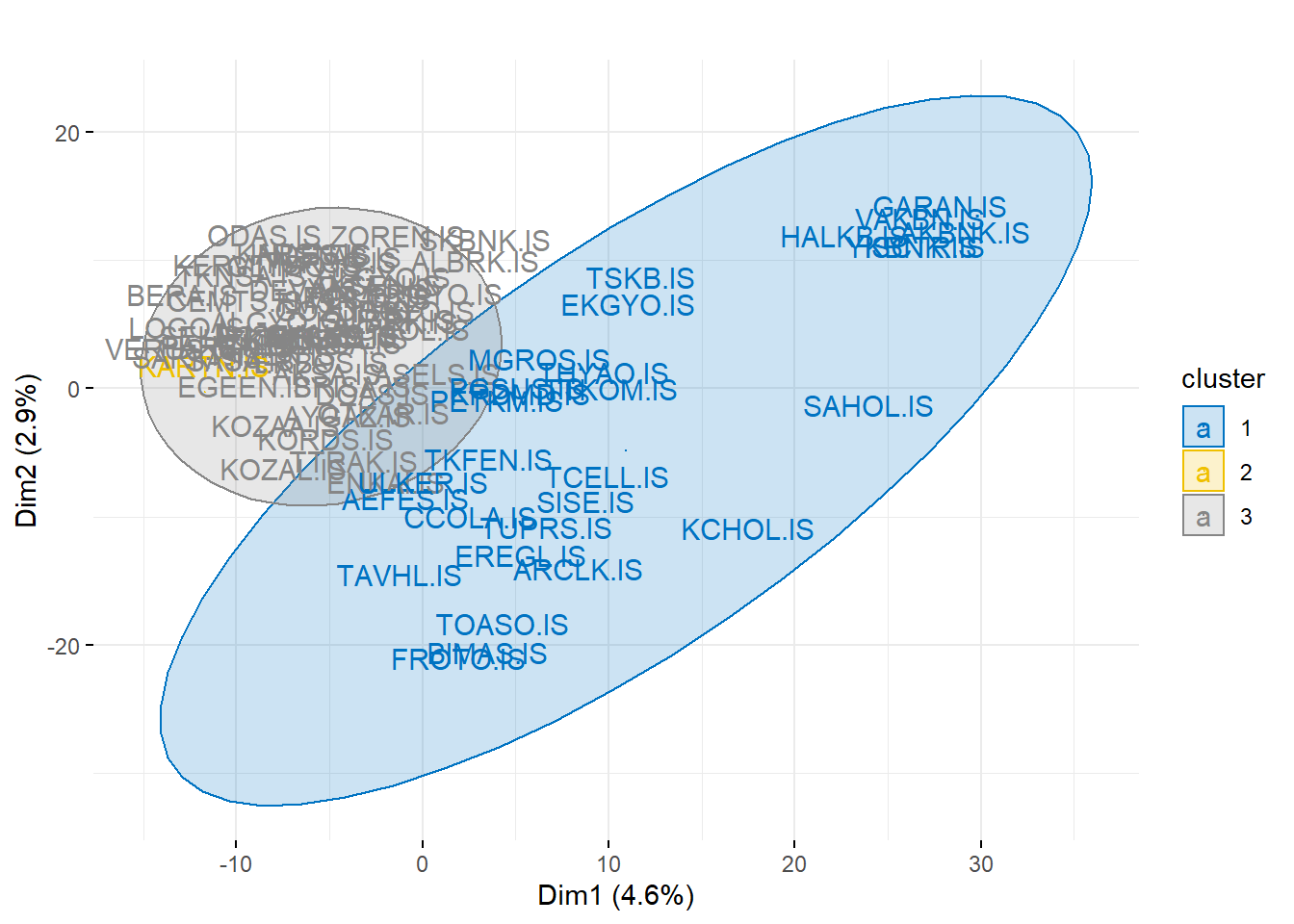
Market Performance and Portfolio Construction
We’ve XU100 daily returns as baseline.
Let’s select one stock from each cluster randomly two times and construct two different portfolios:
# Select two stocks from each cluster randomly
# data.frame(stock=names(km_model$cluster),
# cluster=km_model$cluster) %>%
# group_by(km_model$cluster) %>% sample_n(2)In my run, it selected EGEEN and ECILC from cluster 1, FROTO and THYAO from cluster 2 and AKSA and TTRAK from cluster 3. Construct two different portfolios with them:
stocks <- c("EGEEN.IS", "ECILC.IS", "FROTO.IS", "THYAO.IS", "AKSA.IS", "TTRAK.IS")
weights <- c(
0.34, 0.33, 0.33, 0.0, 0.0, 0.0,
0.0, 0.0, 0.0, 0.34, 0.33, 0.33
)
weights_table <- tibble(stocks) %>%
tq_repeat_df(n = 2) %>%
bind_cols(tibble(weights)) %>%
group_by(portfolio)
portfolio_returns <- daily_returns %>%
filter(date >= daily_returns_p$date[1]) %>%
tq_repeat_df(n = 2) %>%
tq_portfolio(assets_col = symbol,
returns_col = daily.returns,
weights = weights_table,
col_rename = "portfolio.returns")
head(portfolio_returns)Merge daily return data:
daily_returns_portfolios <- left_join(portfolio_returns, market_return, , by="date")
daily_returns_portfoliosCalculate performances, risks, CAPM table:
daily_returns_portfolios %>%
tq_performance(Ra = portfolio.returns, Rb = daily.return, performance_fun = table.CAPM)daily_returns_portfolios %>%
tq_performance(Ra = portfolio.returns, Rb = daily.return, performance_fun = table.DownsideRisk)daily_returns_portfolios %>%
tq_performance(Ra = portfolio.returns, Rb = NULL, performance_fun = table.AnnualizedReturns)Visualize portfolio growths with 1000 TRY initial capital, let’s add the index XU100 to the graph:
stocks <- c("XU100.IS", "EGEEN.IS", "ECILC.IS", "FROTO.IS", "THYAO.IS", "AKSA.IS", "TTRAK.IS")
weights <- c(
1.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0,
0.0, 0.34, 0.33, 0.33, 0.0, 0.0, 0.0,
0.0, 0.0, 0.0, 0.0, 0.34, 0.33, 0.33
)
weights_table <- tibble(stocks) %>%
tq_repeat_df(n = 3) %>%
bind_cols(tibble(weights)) %>%
group_by(portfolio)
portfolio_returns <- daily_returns %>%
filter(date >= daily_returns_p$date[1]) %>%
tq_repeat_df(n = 3) %>%
tq_portfolio(assets_col = symbol,
returns_col = daily.returns,
weights = weights_table,
col_rename = "portfolio.returns")
portfolio_growth_daily <- daily_returns %>%
filter(date >= daily_returns_p$date[1]) %>%
tq_repeat_df(n = 3) %>%
tq_portfolio(assets_col = symbol,
returns_col = daily.returns,
weights = weights_table,
col_rename = "investment.growth",
wealth.index = TRUE) %>%
mutate(investment.growth = investment.growth * 1000)
portfolio_growth_daily %>%
ggplot(aes(x = date, y = investment.growth, color = factor(portfolio))) +
geom_line(size = 2) +
labs(title = "Portfolio Growth",
x = "", y = "Portfolio Value",
color = "Portfolio") +
geom_smooth(method = "loess") +
theme_tq() +
scale_color_tq() +
scale_y_continuous()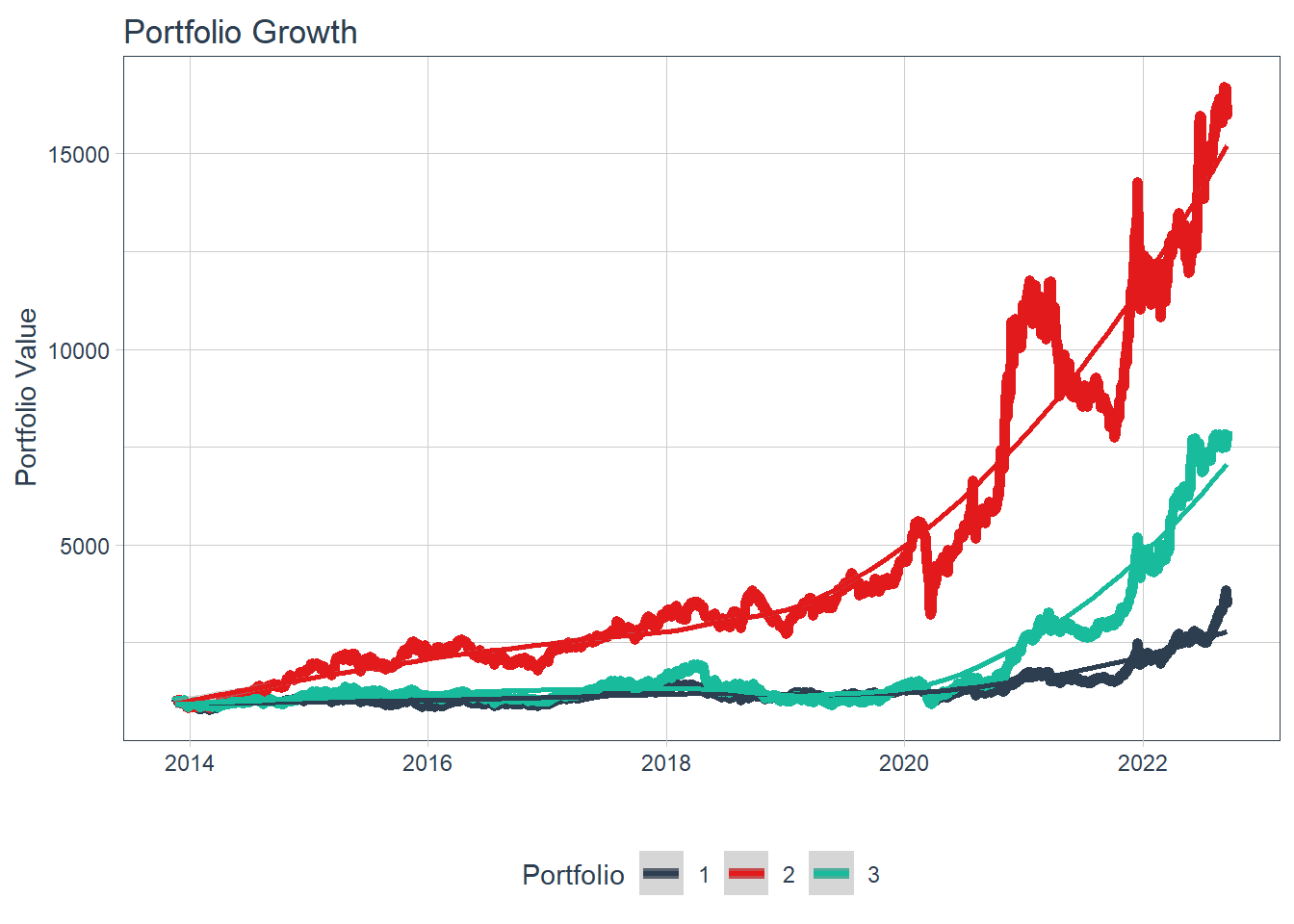
Full source code: https://github.com/mrtkp9993/MyDsProjects/tree/main/StockClusteringDiverse
No matching items
Citation
BibTeX citation:
@online{koptur2022,
author = {Koptur, Murat},
title = {Build {Diversified} {Portfolio} with {Machine} {Learning:}
{Clustering} Method for Stock Selection},
date = {2022-09-18},
url = {https://muratkoptur.com/MyDsProjects/StockClusteringDiverse/Analysis},
langid = {en}
}
For attribution, please cite this work as:
Koptur, Murat. 2022. “Build Diversified Portfolio with Machine
Learning: Clustering Method for Stock Selection.” September 18,
2022. https://muratkoptur.com/MyDsProjects/StockClusteringDiverse/Analysis.