Pekiştirmeli Öğrenme (Reinforcement Learning)'e Giriş ve Temel Kavramlar
2026-01-02 · 5 min read
Pekiştirmeli öğrenme (Reinforcement Learning – RL), bir ajanın (agent), dinamik bir ortam (environment) ile etkileşime girerek, aldığı ödül (reward) sinyallerine dayanarak davranışlarını iyileştirmesini amaçlayan bir makine öğrenmesi yaklaşımıdır. Denetimli öğrenmeden farklı olarak, pekiştirmeli öğrenmede veriler sınıf etiketi içermez. Bunun yerine ajan, uzun vadede toplam ödülü maksimize edecek bir strateji (policy) öğrenmeye çalışır.
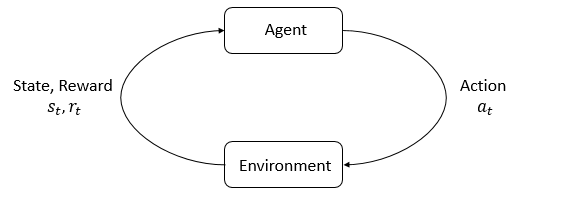
Temel Bileşenler
-
Ajan (Agent): Ajan, ortamla etkileşime giren ve kararlar alan ve öğrenen sistemdir. Örneğin; bir robot, veya bir oyun oynayan yapay zekâ.
-
Ortam (Environment): Ajanın içinde bulunduğu ve eylemlerine karşılık yeni durumlar ve ödüller üreten sistemdir.
-
Durum (State): Ortamın, belirli bir andaki temsilidir. Genellikle ile gösterilir.
-
Gözlem (Observation): Ortamın gerçek durumunun (state) tamamını değil, yalnızca ajan tarafından algılanabilen kısmını temsil eder. Yani gözlem, durumun eksik, gürültülü veya dolaylı bir yansıması olabilir ve bazı bilgileri içermeyebilir.
-
Eylem (Action): Ajanın, bulunduğu durumda seçebileceği hamlelerdir. Genellikle ile gösterilir.
-
Ödül (Reward): Ajanın yaptığı eylemin ne kadar “iyi” olduğunu belirten geri bildirimdir. Pekiştirmeli öğrenmede amaç, beklenen toplam ödülü maksimize etmektir.
-
Politika (Policy): bir ajanın hangi durumda (veya gözlemde) hangi eylemi seçeceğini tanımlayan kuraldır. Determistik ise, belirli bir durumda her zaman aynı eylem seçilir, stokastik olduğu durumda ise, eylemler olasılıksal olarak seçilir,
-
Yörünge (Trajectory - Episode): Durum, eylem ve ödül dizisidir,
-
Ödül (Reward) / Getiri (Return): Ödül fonksiyonu ajanın her adımda yaptığı eylemin anlık sonucunu sayısal bir değer olarak ifade eder. Bir ödül sinyali, mevcut durum, alınan aksiyon ve bir sonraki duruma bağlıdır: . Ajanın amacı anlık ödülleri değil, bir yörünge boyunca elde edeceği toplam ödülü, yani getiriyi maksimize etmektir. Getiri iki farklı şekilde hesaplanabilir:
-
Sonlu-Ufuklu İskontosuz Getiri (Finite-Horizon Undiscounted Return): Belirli bir zaman dilimi veya adım sayısı içinde toplanan ödüllerin toplamıdır:
-
Sonsuz-Ufuklu İskontolu Getiri (Infinite-Horizon Discounted Return): Ajanın tüm ömrü boyunca elde edeceği ödüllerin toplamıdır, ancak gelecekteki ödüller bir iskonto faktörü ile çarpılarak indirgenir:
-
Ortam durum geçişlerinin ve politikanın stokastik olduğunu düşünürsek, -adım yörünge olasılığı aşağıdaki gibi ifade edilir:
Beklenen getiri ise
optimal politika olmak üzere, problem
şeklinde ifade edilir.
Değer Fonksiyonları (Value Functions)
Değer fonksiyonları, bir ajanın uzun vadede ne kadar "iyi" durumda olduğunu veya belirli bir eylemin ne kadar "karlı" olduğunu ölçen, pekiştirmeli öğrenme algoritmalarının temellerini oluşturan fonksiyonlardır.
Politikanın öğrenme sürecindeki rolüne göre iki ana yaklaşım bulunmaktadır. On-policy yakşalımda öğrenilen potilika ve davranılan politika aynıdır. Off-policy yaklaşımda ise aynı olmak zorunda değildir.
- On-policy Durum-Değer fonksiyonu : Durum ve politika iken beklenen getiriyi hesaplar:
- On-policy Eylem-Değer fonksiyonu : Durum iken aksiyonu alınırsa (politikadan olmak zorunda değil) ve daha sonrasında politikası izlenirse elde edilecek beklenen getiriyi hesaplar:
- Optimal Değer fonksiyonu : Durum iken her zaman optimal politikaya göre hareket edilirse beklenen getiriyi hesaplar:
- Optimal Eylem-Değer fonksiyonu : Durum ve herhangi bir aksiyonu alındıktan sonra optimal politika izlenirse beklenen getiriyi hesaplar:
Bellman Denklemleri
Bellman denklemleri, değer fonksiyonlarının kendi kendisiyle tutarlı olmasını sağlayan temel eşitliklerdir. Temel olarak, bir noktadaki “iyi olma” durumu, yalnızca o an kazanılan ödüle değil, sonrasında hangi duruma geçileceğine de bağlı olduğunu belirtir.
On-policy Bellman Denklemleri
Optimal değer fonksiyonları için Bellman denklemleri
Bellman denklemleri, uzun vadeli problemi, tek adımlık güncellemelere indirger ve bir çok pekiştirmeli öğrenme algoritmasının temelini oluştururlar.
Avantaj (Advantage) Fonksiyonu
Pekiştirmeli öğrenmede bazen bir eylemin mutlak olarak ne kadar iyi olduğu ile ilgilenmek yerine, bir eylemin diğer eylemlere göre ortalamada ne kadar iyi olduğu ölçülür. Bu kavram avantaj (advantage) olarak adlandırılır ve Policy Gradient algoritmalarının ana fikrini oluşturur.
Markov Karar Süreçleri (Markov Decision Processes)
Yukarıda anlattığım ajan ve ortam etkileşimi matematiksel olarak Markov karar süreçleri ile tanımlanabilir. Bir Markov karar süreci (kısaca MDP) aşağıdaki 5 bileşenden oluşur:
Burada:
- ortamdaki tüm durumların kümesi,
- ajanın seçebileceği tüm geçerli eylemlerin kümesi,
- ödül fonksiyonu,
- geçiş olasılığı fonksiyonu ve
- başlangıç durum dağılımıdır.
Keşif (Exploration) vs. Kullanım (Exploitation)
Kullanım, ajanın o ana kadar en yüksek ödülü getirdiğini bildiği, güvenilir ve test edilmişeylemi tekrar tekrar seçmesidir. Amaç, mevcut bilgiyle en iyi ödülü almaktır.
Keşif ise ajanın daha önce az denediği, sonucu belirsiz ve sısa vadede kötü sonuçlar verebilecek eylemleri bilerek denemesidir. Bu davranıştaki amaç daha iyi bir eylem var mı sorusuna yanıt aramaktır.
Başarılı bir pekiştirmeli öğrenme algoritması, doğru keşif - kullanım dengesini kurmalıdır.
Pekiştirmeli Öğrenme Algoritmalarının Sınıflandırılması
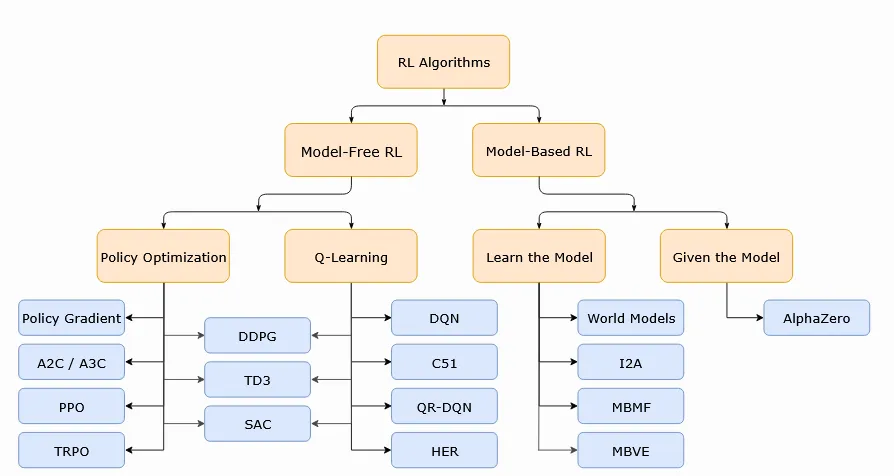
Model-based algoritmalarda ajan ortamın nasıl çalıştığını bilir ya da öğrenebilir. Bunun avantajı, ajanın planlama yapabilmesidir. Avantajı, daha az veri ile daha hızlı öğrenebilmesidir ancak eğer ortam modeli hatalıysa, ajan gerçek ortamda başarısız olur.
Model-free algoritmalarda ise böyle bir varsayım yoktur. Model-free algoritmalarda genel olarak iki farklı yaklaşım bulunmaktadır:
-
Politika Optimizasyonu (Policy optimization): Ajan, doğrudan politikayı öğrenir. A2C, A3C, PPO gibi algoritmalar bu yöntemi kullanır.
-
Q-Learning: Bu yöntemde ajan, aksiyonların değerlerini öğrenir. DQN gibi popüler algoritmalar bu yöntemi kullanır.
-
Actor-Critic: İki yöntemi birleşimidir, politika öğrenen bir aktör ve onu "eleştiren" bir kritik (Q-fonksiyonu) vardır. DDPG, TD3, SAC gibi algoritmalar bu yöntemi kullanır.
Bir sonraki yazıda görüşmek üzere.