Multi Armed Bandit
2026-01-18 · 3 min read
Multi-Armed Bandit (yazının devamında kısaca MAB diyeceğim) problemi, belirsizlik altında karar verme, öğrenme ve optimizasyon konularının merkezinde yer alan klasik bir pekiştirmeli öğrenme problemidir. Adını, her kolu farklı ve bilinmeyen ödül dağılımına sahip olan slot makinelerinden alır. Amaç, zaman içinde hangi kolun seçileceğini öğrenerek toplam beklenen ödülü maksimize etmektir. Bu problem, keşif (exploration) ve kullanım (exploitation) arasındaki dengeyi ele alır.
MAB problemi, reklam tıklamaları, klinik deneyler gibi bir çok gerçek uygulamada karşımıza çıkar.
MAB probleminde seçilen aksiyonlar ortamın durumunu (ödül dağılımını) değiştirmez! Bu nedenle MAB, pekiştirmeli öğrenmenin en sade ve özel durumu olarak düşünülebilir.
Matematiksel İfade
Bir MAB problemi aşağıdaki bileşenlerden oluşur:
-
Kollar (Arms): adet eylem vardır ve bu eylemlerin her birinin ödül dağılımı farklıdır.
-
Ödül (Reward): Seçilen kol, rastgele bir ödül üretir:
Burada , . kolun bilinmeyen ödül dağılımıdır.
- Zaman: Kararlar sıralı olarak verilir, .
Herhangi bir anında, sadece seçilen kola ilişkin ödül gözlemlenir, diğer kollar hakkında bilgi edinilemez.
MAB probleminin amacı, toplam beklenen ödülü maksimize etmektir:
Bandit algoritmalarının performansı regret (algoirtmanın, ideal stratejiye göre ne kadar kaybettiği) ile ölçülür:
Burada, en iyi kolun beklenen ödülüdür. Amaç 'yi sub-linear yapmaktır. Bu sayede algoritma zaman ilerledikçe optimale yakın davranmaya başlar.
Politikalar
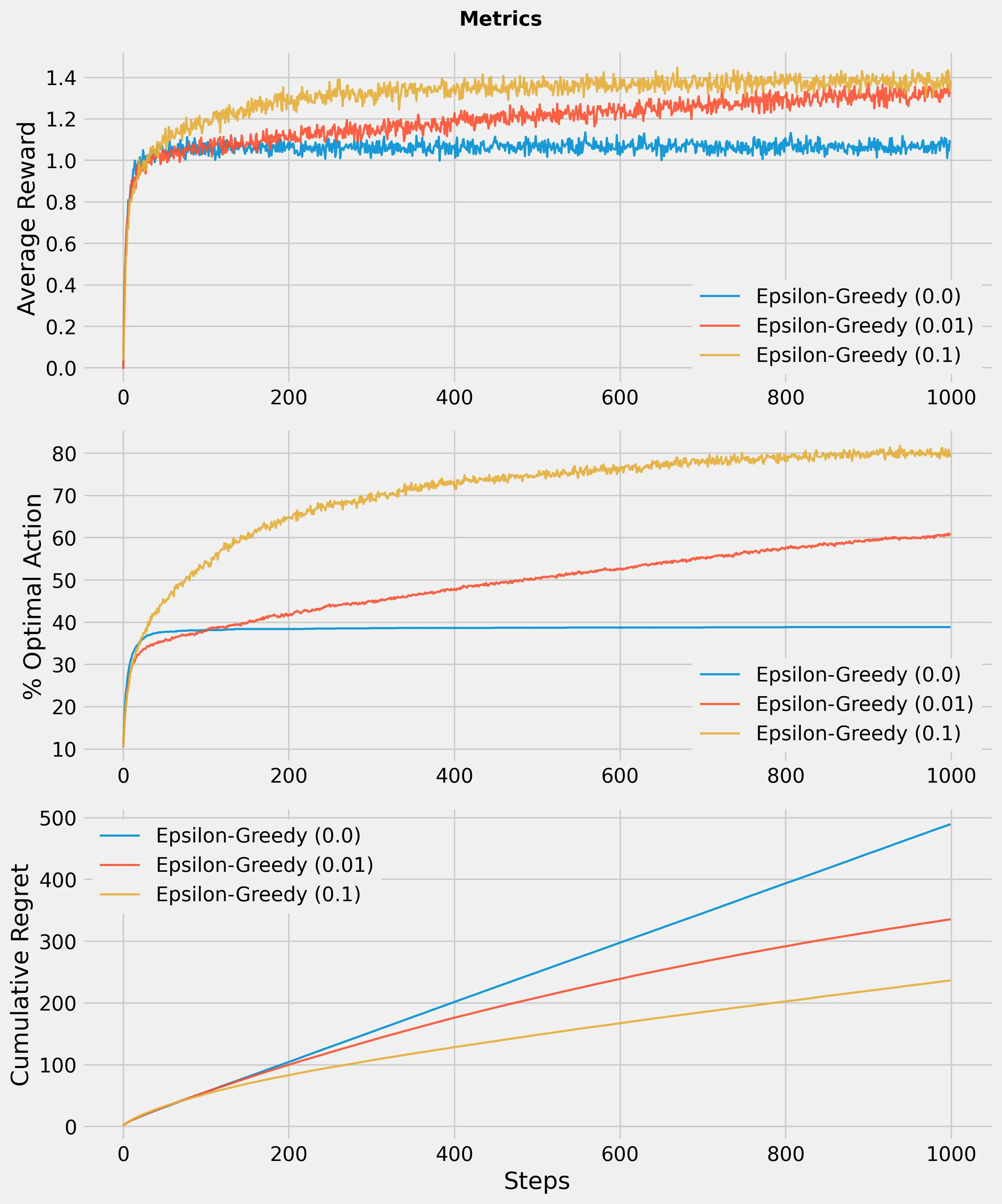
Epsilon-Greedy ( - greedy)
Her bir adımda
- olasılıkla rastgele bir kol seçerek keşif yapar;
- olasılıkla o ana kadar en yüksek ortalama ödüle sahip kolu seçer.
Basit ve etkili bir algoritma olmasına rağmen, sabit olduğundan zamanla daha az keşif yapılmasını sağlamaz; kötü kolları halen denemeye devam edebilir.
Softmax
Kolların seçilme olasılıklarını sıcaklık (temperature) parametresiyle normalize eder:
Bu sayede iyi kollara odaklanırken düşük ödüllü kollara da şans verir.
Upper Confidence Bound (UCB)
Her bir kolun ortalama ödülüne bir güven sınırı ekler ve en yüksek üst sınıra sahip kolu seçer. Az denenmiş kolların güven sınırları daha büyük olacağından doğal olarak keşif imkanı sağlar:
Thompson Sampling
Her bir kol için tek bir ortalama değer tutmak yerine ödül dağılımını tutar ve her adımda bu dağılımdan örneklem yapar ve en yüksek değere sahip kolu seçer.
MAB probleminin Daha Genel Halleri
Klasik MAB probleminde her kolun ödül dağılımı sabit ve zamandan bağımsızdır. Ancak gerçek dünyada bu varsayım çoğu zaman geçerli değildir. Bu nedenle literatürde MAB’nin daha genel ve güçlü iki önemli uzantısı geliştirilmiştir: Contextual Bandits ve Adversarial Bandits.
Contextual Bandits
Contextual Bandit problemlerinde, her karar anında ortama dair ek bilgi (bağlam - context) gözlemlenir. Politika bağlama bağlı olarak bir aksiyon seçer. LinUCB algoritması bu tür bir algoritmadır.
Adversarial Bandits
Adversarial Bandit problemlerinde ödüller sabit bir olasılık dağılımından gelmez. Aksine, ortam "kötü niyetli" bir rakip gibi davranarak ödülleri algoritmayı yanıltacak veya en kötü duruma (worst-case) düşürecek şekilde belirleyebilir. Bu nedenle klasik olasılıksal varsayımlar yapılamaz. Algoritmanın performansı, geriye dönük olarak her zaman en iyi kolu seçen bir stratejiye kıyasla ölçülür (Pişmanlık - Regret minimizasyonu). EXP3 algoritması bu tür bir algoritmadır.